在前两篇关于数据库存储与索引技术的探讨中,我们介绍了B+树等传统索引结构及其在磁盘友好型场景下的优势。随着大数据和实时写入密集型应用的兴起,一种名为“日志结构合并树”(Log-Structured Merge-Tree,简称LSM树)的设计脱颖而出,它通过巧妙的“写入优化”思想,极大地提升了系统的写入吞吐量。本文将深入剖析LSM树的一个典型实现案例,并探讨其如何作为核心引擎,支撑起现代数据处理与存储支持服务。
一、LSM树核心思想回顾
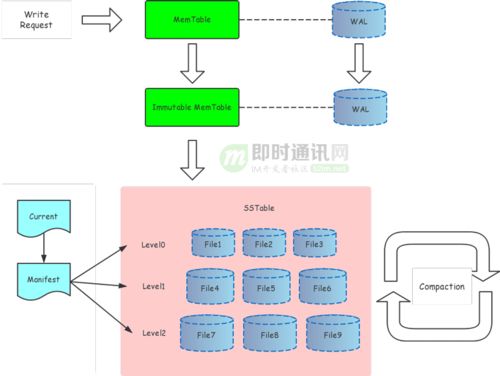
LSM树的核心设计哲学是将随机写入转换为顺序写入,从而充分利用磁盘(尤其是HDD)或新型存储介质的顺序I/O高性能。其基本架构通常包含以下关键组件:
- 内存表(MemTable):所有写入操作首先被追加到内存中的有序数据结构(如跳表、AVL树)中,实现极快的写入速度。
- 不可变内存表(Immutable MemTable):当MemTable达到一定大小阈值后,会转换为只读状态,成为Immutable MemTable,等待被持久化到磁盘。
- Sorted String Table(SSTable):Immutable MemTable中的数据被顺序写入磁盘,形成一个个不可变的、内部有序的数据文件,即SSTable。每个SSTable还附带一个稀疏索引(Bloom Filter等)以加速查询。
- 合并(Compaction):随着SSTable数量的增多,系统会定期将多个旧的、可能存在重复或已删除键的SSTable合并成新的、更大的SSTable,并清理无效数据。这个过程是LSM树后台的核心操作。
二、经典实现案例:LevelDB/RocksDB
LevelDB(由Google开发)及其高性能分支RocksDB(由Facebook优化)是LSM树思想最著名、应用最广泛的开源实现。它们常被用作嵌入式键值存储引擎,支撑着众多大型分布式系统。
1. 数据组织:层级结构
LevelDB/RocksDB采用了分层的SSTable组织方式(Leveled Compaction)。磁盘上的SSTable被组织成多个层级(L0, L1, L2...)。
- L0层:由Immutable MemTable直接刷盘生成,允许SSTable之间的键范围重叠。
- L1及更深层:每层的数据量呈指数增长(例如10倍),且同一层内的SSTable键范围互不重叠,且全局有序。这种结构极大地优化了范围查询的效率。
2. 关键流程
- 写入流程:写入键值对 → 追加到WAL(Write-Ahead Log,用于崩溃恢复) → 插入MemTable → 返回成功。整个过程几乎全是内存操作和顺序磁盘追加,速度极快。
- 读取流程:查询键 → 首先查找MemTable → 再查找Immutable MemTable → 最后从L0到最深层的SSTable中逐层查找。为加速查找,除了每层的文件元数据索引,还广泛使用Bloom Filter来快速判断一个键是否绝对不存在于某个SSTable中,从而避免大量不必要的磁盘I/O。
- 合并流程(Compaction):这是后台持续进行的核心任务。当某一层的数据量超过阈值时,会从该层选取一个或多个SSTable,与下一层键范围有重叠的SSTable进行多路归并排序,生成新的、有序的SSTable写入下一层,并删除旧的输入文件。这个过程有效控制了SSTable的总数,并持续进行数据整理与垃圾回收。
3. 优势与权衡
- 优势:极高的写入吞吐量;出色的空间放大率(特别是使用Leveled Compaction时);为顺序I/O优化。
- 权衡:读取操作可能涉及多次I/O(需要权衡内存大小、BloomFilter精度和层级数);写入放大(Compaction过程中数据被反复重写);在某些工作负载下可能产生较高的延迟毛刺(由后台Compaction引起)。RocksDB针对这些权衡做了大量优化,如可调的Compaction策略、多线程Compaction、更精细的速率限制等。
三、作为数据处理与存储支持服务的引擎
LSM树引擎(以RocksDB为代表)本身并非直接面向终端用户的服务,而是作为核心的“存储引擎”或“数据内核”,嵌入到更上层的、功能完备的数据处理与存储支持服务中。其应用模式主要体现在以下几个方面:
1. 分布式数据库/键值存储的存储层
许多著名的分布式系统使用RocksDB作为每个节点本地数据的存储引擎。例如:
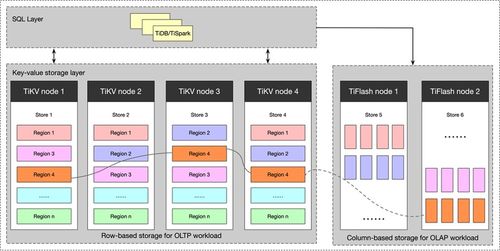
- TiKV:TiDB分布式数据库的分布式键值存储层,使用RocksDB存储Region数据,支撑了TiDB强大的HTAP能力。
- CockroachDB:其每个节点的存储层同样基于RocksDB构建。
- Apache Cassandra / ScyllaDB:这些宽列数据库的本地存储引擎也深受LSM树思想影响,或直接集成RocksDB。
在这些系统中,LSM树引擎负责高效的本地数据持久化、排序和检索,而上层服务负责分布式事务、一致性协议、数据分片、副本管理、SQL接口等。
2. 流处理与事件存储
在Kafka或Pulsar等消息队列中,需要持久化大量的有序消息日志。LSM树顺序写入的特性非常适合此类场景。例如,Apache Pulsar的“分层存储”特性可以使用RocksDB来管理已消费消息的索引和元数据,实现高效的老数据卸载与检索。
3. 时序数据库(TSDB)
时序数据具有高并发写入、按时间范围查询为主的特点。许多时序数据库(如InfluxDB的存储引擎Time Structured Merge Tree - TSM,其思想与LSM同源)或基于RocksDB构建的时序数据库方案,利用LSM树高效处理时间序列数据的批量写入和按时间窗口的压缩合并。
4. 搜索引擎的倒排索引存储
搜索引擎需要快速更新和合并倒排索引列表。LSM树“先内存后磁盘、定期合并”的模式,天然适合处理这种增量更新的索引数据,能够平衡索引的实时更新性与查询性能。
四、
LSM树通过其独特的“以顺序I/O换写入性能”的设计,成功解决了高吞吐写入场景下的传统B+树瓶颈。以LevelDB/RocksDB为代表的实现,通过层级化SSTable、Bloom Filter、可配置的合并策略等精巧设计,将这一理论模型工程化、高性能化。如今,它已不仅仅是学术界的一个概念,更是现代数据处理与存储基础设施中不可或缺的“基石”组件。从分布式数据库到消息队列,从时序数据到搜索引擎,LSM树引擎作为核心的存储支持服务,在幕后默默支撑着互联网时代海量数据的实时写入与可靠存储,是构建高性能、可扩展数据系统的关键选择之一。理解其原理与实现,对于设计和优化数据密集型应用至关重要。