在销售数据仓库建立的第一步完成需求分析与架构规划后,第二步是将其落地的核心工程阶段。此阶段聚焦于数据的物理迁移、结构化设计以及处理能力的构建,为后续的数据分析与决策支持奠定坚实基础。本步骤主要包含四个关键环节:数据迁移、数据仓库事务表设计、存储过程设计,以及数据处理与存储支持服务。
一、数据迁移:从源系统到数据仓库的桥梁
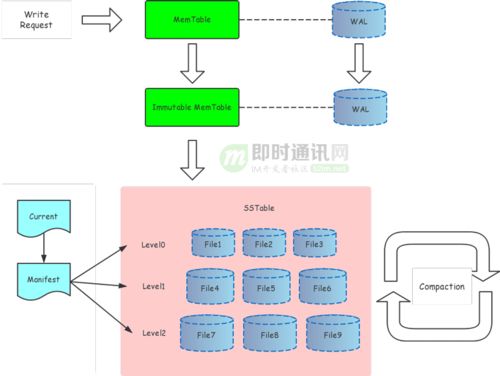
数据迁移是将分散在各个业务系统(如CRM、ERP、订单系统)中的历史与增量销售数据,抽取、清洗、转换并加载(ETL过程)到数据仓库中的过程。这是构建数据仓库的“奠基”工程。
- 策略制定:需明确迁移范围(全量/增量)、迁移频率(实时/准实时/每日批处理)与数据一致性要求。对于销售数据,初始通常需要一次全量历史数据迁移,后续通过增量迁移保持同步。
- ETL/ELT流程开发:
- 抽取(Extract):从源系统安全、高效地获取数据,需处理不同数据源(结构化数据库、日志文件、API接口)的连接与读取。
- 转换(Transform):这是核心清洗环节。针对销售数据,需统一商品编码、客户ID、日期格式;处理缺失值、异常值(如负销售额);进行业务逻辑计算(如计算折扣后净销售额、毛利润)。
- 加载(Load):将清洗转换后的数据加载到数据仓库的ODS(操作数据存储)层或直接加载到维度模型中。
- 迁移验证与回滚方案:必须建立严格的数据质量校验规则(如记录数核对、关键指标汇总比对),并准备应急预案,确保迁移过程可靠。
二、数据仓库事务表设计:构建星型/雪花型模型
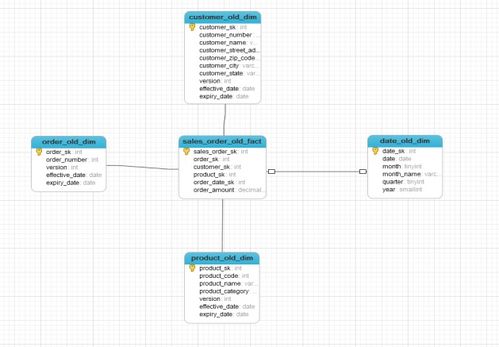
数据仓库的表结构设计通常采用维度建模,以优化查询性能和分析效率。对于销售业务,最核心的是构建以“销售事实表”为中心的星型模型。
- 事实表设计:
- 核心事务表:销售订单事实表。其主键通常为复合键,包含多个维度键。事实(度量)包括:销售数量、销售额、成本、折扣金额、税费等可累加的数字指标。
- 事务粒度:每条记录代表一笔订单或一个订单明细项,这是最细颗粒度,保证了最大分析灵活性。
- 维度表设计:围绕事实表,设计一系列描述性维度表,提供分析视角:
- 时间维度:年、季度、月、日、节假日标志,是销售分析最重要的切片维度。
- 产品维度:产品ID、名称、类别、品牌、价格段等。
- 客户维度:客户ID、 demographics信息、客户等级、所属区域等。
- 渠道/店铺维度:线上线下渠道、门店ID、地理位置、经理等。
- 员工维度:销售员、客服等。
- 维度表应使用代理键(自增ID)与事实表关联,以处理缓慢变化维(SCD)问题,例如客户地址变更。
三、存储过程设计:自动化与业务逻辑封装
存储过程在数据仓库中扮演着“自动化引擎”和“逻辑容器”的角色,主要用于调度复杂的ETL任务和实现可重用的数据加工逻辑。
- ETL作业调度:创建存储过程来封装每个ETL步骤(如“抽取订单数据”、“清洗客户信息”),并通过作业调度工具(如SQL Server Agent, Apache Airflow)按依赖关系和时间顺序自动执行,形成完整的数据流水线。
- 数据清洗与转换逻辑:将复杂的清洗规则(如识别并标记异常交易)、多表关联和计算逻辑(如生成月度销售汇总中间表)编写成存储过程,提高代码复用性和可维护性。
- 维度管理:编写处理缓慢变化维(SCD)的存储过程,例如当产品信息更新时,是覆盖(Type 1)还是新增历史记录(Type 2)。
- 性能优化:通过存储过程,可以更精细地控制事务边界和批量操作,提升大数据量处理效率。
四、数据处理和存储支持服务:确保系统健壮与高效
此部分是为整个数据仓库提供稳定、高效运行的底层支撑环境与服务。
- 计算与处理服务:
- 根据数据处理量(日增量、历史总量)和复杂度,选择合适的计算资源(如高性能数据库集群、大数据处理平台如Spark)。
- 设计并实施合理的资源队列和优先级策略,确保ETL作业、即席查询和报表生成任务互不干扰。
- 存储管理与优化:
- 分层存储:明确数据仓库各层(ODS、DWD明细层、DWS汇总层、ADS应用层)的存储策略与生命周期管理(如明细数据保留7年,汇总数据永久保留)。
- 分区与索引:对大型事实表(尤其是销售订单表)按时间(如按月)进行分区,可极大提升查询和维护效率。针对高频查询条件(如产品类别、区域)建立合适的索引。
- 压缩与归档:对历史冷数据实施数据压缩,节省存储空间;制定归档策略,将极少访问的数据移至成本更低的存储介质。
- 监控与运维支持:
- 建立监控体系,跟踪ETL作业运行状态、耗时、数据质量指标、存储空间使用率和查询性能。
- 设置告警机制,对作业失败、数据延迟、空间不足等情况及时通知运维人员。
- 提供日常的数据维护服务,如索引重建、统计信息更新、存储空间扩容等。
###
数据仓库建立的第二步是将蓝图转化为实体的关键构建阶段。通过严谨的数据迁移确保数据资产完整、准确地入库;通过科学的事务表设计(维度模型)构建易于理解和高效查询的数据结构;通过高效的存储过程设计实现数据处理流程的自动化和逻辑封装;通过强大的数据处理和存储支持服务保障整个系统稳定、高性能地持续运行。这四个环节环环相扣,共同构成了数据仓库的“躯干”与“神经系统”,为后续的数据分析、报表展现和商业智能应用提供了纯净、统一、可靠的数据源。