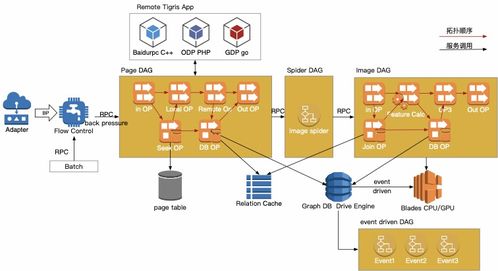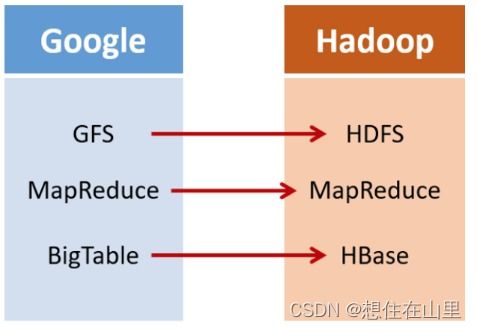
在数据科学与人工智能领域,高效的数据处理与可靠的存储服务是项目成功的基石。Datawhale作为开源学习社区,在其Task 1中重点探讨了这一主题,旨在帮助学习者构建坚实的数据基础。本文将深入解析数据处理与存储支持服务的关键环节,为实践提供清晰指引。
一、数据处理:从原始数据到可用信息
数据处理是将原始数据转化为结构化、清洁、可用于分析或建模格式的过程。这一阶段通常包括数据采集、清洗、转换与集成。
- 数据采集:涉及从数据库、API、日志文件或网页爬虫等多种源获取数据。关键考量包括数据源的可靠性、实时性需求以及合规性(如GDPR)。
- 数据清洗:处理缺失值、异常值、重复记录和不一致格式。例如,使用Pandas库的
dropna()、fillna()方法,或通过正则表达式标准化文本数据。 - 数据转换:包括归一化、离散化、特征工程等操作,以适配模型需求。Scikit-learn的
StandardScaler或OneHotEncoder是常用工具。 - 数据集成:合并多源数据,解决实体识别与属性冲突问题,形成统一数据集。
二、存储支持服务:保障数据可访问性与安全性
存储服务不仅关乎数据保存,更涉及高效检索、扩展性与灾备能力。根据数据特性,可选择以下方案:
- 关系型数据库(如MySQL、PostgreSQL):适用于结构化数据,支持ACID事务,适合财务、用户管理等场景。
- NoSQL数据库(如MongoDB、Redis):应对非结构化或半结构化数据,提供高并发读写能力,常用于日志存储、实时推荐系统。
- 数据仓库(如Amazon Redshift、Snowflake):专为OLAP设计,支持复杂查询与大数据分析,集成ETL工具提升效率。
- 云存储服务(如AWS S3、Google Cloud Storage):提供高可扩展对象存储,适合备份、多媒体文件及数据湖架构。
三、实践策略与工具链整合
在Datawhale任务实践中,建议采用以下流程:
- 使用Apache Airflow或Prefect编排数据处理流水线,实现自动化调度。
- 结合Docker容器化部署,确保环境一致性。
- 利用Metabase或Superset等工具实现数据可视化监控。
关注数据版本控制(如DVC)与元数据管理,可提升团队协作效率。
四、挑战与未来趋势
当前数据处理面临数据量指数增长、实时性要求提高及隐私保护法规细化等挑战。边缘计算与云边协同架构正逐步兴起,以减少传输延迟。湖仓一体(Lakehouse)概念融合数据湖灵活性与数据仓库管理能力,成为新兴方向。机器学习赋能的数据管理(如自动数据清洗)也值得关注。
数据处理与存储是数据价值链的起点。通过系统化掌握Datawhale Task 1的核心内容,学习者不仅能构建稳健的数据管道,更能为后续分析与模型开发奠定坚实基础。持续关注技术演进,灵活选用工具与服务,方能在数据洪流中把握先机。