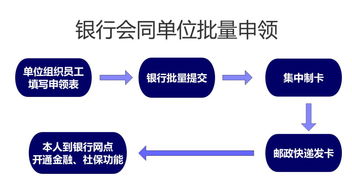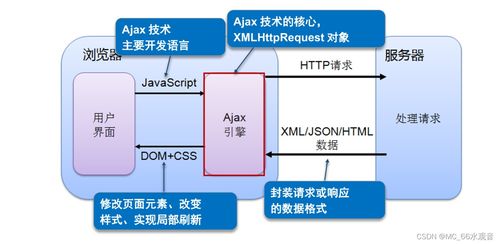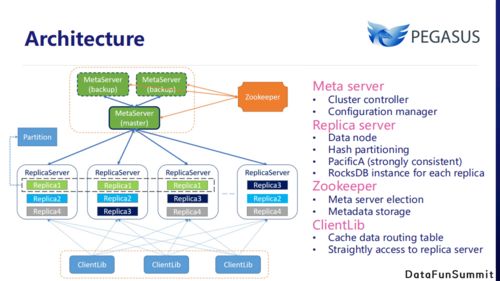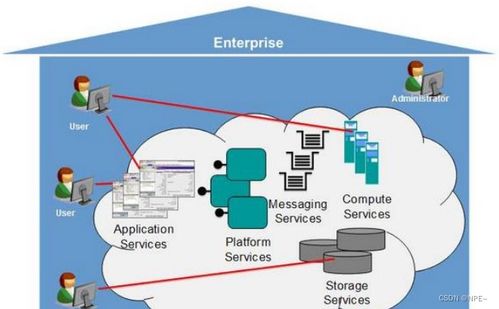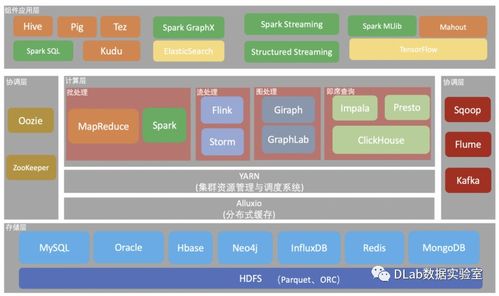
在当今数据驱动的时代,大数据计算生态构成了企业数字化转型和智能决策的核心引擎。这个庞大而精密的体系并非孤立存在,其高效运转仰赖于三个紧密协作、互为支撑的支柱:数据存储、数据处理以及数据处理和存储支持服务。它们共同构成了从数据原始状态到价值洞察的完整闭环。
一、 数据存储:海量信息的稳固根基
数据存储是大数据生态的“记忆体”,其核心任务是解决海量、多源、异构数据的持久化保存与高效访问问题。它已从传统的集中式架构,演进为适应大数据特性的分布式、高可扩展形态。
- 分布式文件系统:以Hadoop HDFS为代表,它将超大规模数据集(PB级以上)分割成块,分散存储于廉价的商用服务器集群中,通过冗余机制确保高容错性,为批处理提供了高吞吐量的数据访问基础。
- NoSQL数据库:针对关系型数据库在处理非结构化、半结构化数据及高并发写入时的瓶颈应运而生。例如:
- 键值存储(如Redis, DynamoDB):适用于高速缓存和会话存储。
- 列式存储(如HBase, Cassandra):擅长快速查询海量数据集中的特定列,适合实时读写。
- 文档数据库(如MongoDB):以灵活的JSON/BSON格式存储,适配快速演变的业务模型。
- 图数据库(如Neo4j):专注于实体间复杂关系的存储与遍历。
- 数据湖与数据仓库:
- 数据湖(通常基于HDFS、对象存储如AWS S3)存储原始、未经加工的全量数据,格式不限,支持探索式分析。
- 数据仓库(如Teradata、Snowflake、ClickHouse)则存储经过清洗、整合、建模的结构化数据,为商业智能(BI)和报表提供高性能查询。现代架构常呈现“湖仓一体”趋势,以融合两者的优势。
二、 数据处理:释放数据价值的核心引擎
数据处理是赋予数据生命力的“转化器”,负责对存储层中的数据进行计算、分析和挖掘。根据时效性和计算模式,主要分为批处理、流处理和交互式查询。
- 批处理:处理静态的、累积成“批”的历史数据,追求高吞吐量。Apache Spark 是当前主流框架,其内存计算和DAG执行引擎大幅提升了批处理性能,取代了早期的MapReduce。它支持SQL、流处理、机器学习等多种工作负载。
- 流处理:处理连续不断产生的实时数据流,追求低延迟。代表框架有:
- Apache Flink:提供真正的流式处理语义(事件时间、状态管理),并统一批流API,是高性能实时计算的标杆。
- Apache Kafka Streams:轻量级库,用于在Kafka消息系统内部直接构建实时应用。
- Apache Storm / Samza 等也在特定场景下应用。
- 交互式查询与分析:为用户提供亚秒级到秒级的快速数据探查能力。例如:
- Apache Hive:基于Hadoop的SQL引擎,将SQL转化为MapReduce/Spark/Tez作业。
- Presto / Trino:分布式SQL查询引擎,可跨多种数据源(HDFS, S3, RDBMS等)进行联邦查询,无需移动数据,速度极快。
- 机器学习与图计算:Spark MLlib、Flink ML 提供了分布式算法库,TensorFlow、PyTorch 也可与大数据平台集成进行大规模训练。图计算则有 GraphX(基于Spark)等框架支持。
三、 数据处理和存储支持服务:生态高效运转的“润滑剂”与“脚手架”
这一层是确保数据存储与处理流程可靠、高效、安全、可管理的关键支撑体系,常被忽视却至关重要。
- 资源管理与调度:
- Apache YARN:Hadoop 2.0的核心组件,作为集群的“操作系统”,负责统一管理计算资源(CPU、内存)并在其上调度如MapReduce、Spark等计算框架的任务。
- Kubernetes:云原生时代的事实标准,正逐渐成为大数据工作负载(通过Spark on K8s, Flink on K8s等)的调度和管理平台,提供更优的隔离性、弹性和混合云部署能力。
- 数据集成与传输:
- Apache Kafka:分布式流数据平台,充当高吞吐、可持久化的实时数据管道,连接数据源与处理应用,是流生态的“中枢神经系统”。
- Apache Sqoop:用于在Hadoop和关系型数据库间高效传输批量数据。
- Apache Flume / Logstash:用于日志等流式数据的采集、聚合和传输。
- 元数据与数据治理:
- Apache Atlas、Hive Metastore:提供数据资产的分类、血缘追踪、审计和治理功能,确保数据的可发现性、可理解性与合规性。
- 工作流编排与调度:
- Apache Airflow、DolphinScheduler:以代码方式定义、调度和监控复杂的数据处理流水线(DAG),是数据工程自动化的核心工具。
- 安全与访问控制:
- Kerberos 认证、Apache Ranger / Sentry 授权管理,确保集群访问和数据操作的安全性。
###
大数据计算生态是一个动态演进、分层解耦但又高度协同的有机整体。数据存储层如同广阔的土地与仓库,奠定了容量与持久性的基础;数据处理层则是其上繁忙的工厂与实验室,将原始材料转化为高价值产品;而各类支持服务则是连接各环节的道路网络、电力系统、管理章程与安全警卫,保障整个生态的稳定、高效与有序运行。理解这三者之间的互动关系,是设计和构建一个健壮、灵活、可持续的大数据平台的关键所在。随着云原生、人工智能与实时化的深入融合,这一生态将持续向着更智能、更统一、更易用的方向演进。