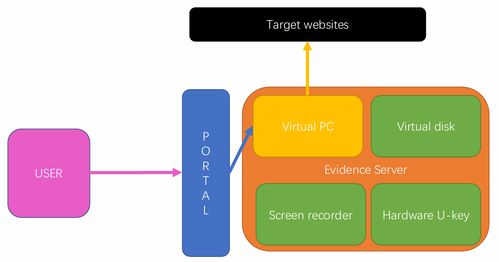
随着微信用户量和业务复杂度的指数级增长,后台系统每日需要处理与存储的海量数据(如消息记录、状态更新、监控指标、日志流等)对传统存储架构提出了严峻挑战。为了应对这一挑战,微信团队设计并实践了一套基于时间序(Time-Series)的新一代海量数据存储架构。该架构不仅高效承载了微信核心业务的数据洪流,也为上层的数据处理与分析提供了稳定、高性能的支持服务。
一、 挑战与设计目标
微信数据洪流具有鲜明的时序特征:数据按时间顺序持续产生、写入密集型、近期数据访问频繁、历史数据主要用于批量分析与归档。传统的关系型数据库或通用NoSQL数据库在处理此类场景时,往往在写入吞吐量、存储成本、查询效率等方面存在瓶颈。因此,新架构的设计目标明确为:
- 高吞吐写入:支持每秒数百万甚至更高量级的数据点写入。
- 低成本存储:利用数据随时间推移而价值衰减的特性,实现分级压缩与存储,大幅降低海量历史数据的存储成本。
- 高效时序查询:针对时间范围、数据聚合(如降采样、求和、求平均)等典型查询模式进行深度优化。
- 高可用与可扩展性:架构本身需具备水平扩展能力,并能容忍节点故障,确保服务持续可用。
- 生态兼容性:能够良好支持监控告警、实时分析、离线批处理等多种数据处理场景。
二、 核心架构设计
微信的时序数据存储架构采用分层、分布式的设计思想,核心组件包括:
- 接入层:负责接收来自全球各地数据中心的数据写入请求。该层采用无状态设计,具备负载均衡和协议适配能力,能够将数据高效转发至存储层。它会对数据进行初步的校验与缓存,以应对流量尖峰。
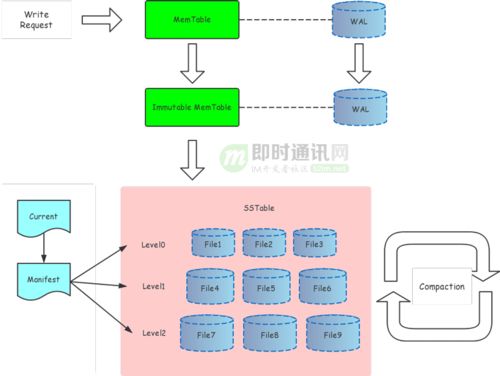
- 存储引擎层:这是架构的核心。微信借鉴并深度定制了开源时序数据库(如InfluxDB、TDengine的设计理念),自主研发了高性能时序存储引擎。其关键设计包括:
- 列式存储与高效压缩:按时间线和指标进行列式存储,并对同一时间线的连续数据点采用针对时序数据优化的压缩算法(如Gorilla、Facebook的Gorilla变种等),极大提升压缩率。
- 时间分区与索引:数据按固定时间窗口(如按天、按小时)进行分区。每个分区内构建基于时间戳和数据标签(tags)的混合索引,实现按时间范围和维度属性的快速数据定位。
- TTL(生存时间)与分级存储:为不同业务数据设置不同的TTL策略。热数据存储在高速SSD上,温数据自动迁移至成本更低的HDD或对象存储,冷数据则进一步归档至深度冷存储系统,实现存储成本的整体优化。
- 计算查询层:提供统一的SQL-like查询接口(如类InfluxQL、PromQL或自定义的TSQL),支持丰富的聚合函数和窗口操作。该层与存储引擎紧密协同,能将查询下推至存储节点,并行执行,并支持流式处理与批量分析任务的统一接入。
- 元数据管理:独立的服务用于管理所有时间序列的元信息(如指标名、标签集合、存储位置等)。采用高可用的分布式共识协议(如Raft)保证元数据的一致性,并缓存于各节点以加速查询。
三、 数据处理与存储支持服务实践
基于上述存储架构,微信构建了完整的数据处理与存储支持服务体系:
- 实时监控与告警:存储架构原生支持高频率数据写入与毫秒级查询延迟,使得业务指标、系统性能的实时监控成为可能。结合流式计算框架,可实现复杂的异常检测与实时告警。
- 数据分析与挖掘:为数据科学家和业务分析师提供统一的数据访问入口。无论是交互式的Ad-hoc查询,还是定期的离线报表生成,都能基于同一套存储获得一致的数据视图。存储引擎对聚合查询的优化显著提升了分析效率。
- 容量规划与成本控制:通过精细化的数据分级存储策略和TTL管理,在满足业务需求的前提下,实现了存储成本的显著下降。架构的水平扩展能力使得容量规划可以按需进行,避免了资源的过度预留。
- 高可用保障:数据在写入时即在多个存储节点间进行多副本复制,确保单点故障不影响数据可靠性与服务可用性。存储节点的弹性扩缩容可在业务无感的情况下完成。
四、 与展望
微信基于时间序的新一代海量数据存储架构,是其应对超大规模、高增长业务数据的基石。该架构通过针对时序数据特征的深度定制,在性能、成本和可靠性之间取得了卓越的平衡。其实践证明,面向特定数据模式(如时间序)设计专用存储系统,是解决互联网海量数据挑战的有效路径。随着5G、物联网等技术的普及,时序数据的规模与价值将进一步爆发。微信团队将持续在存储引擎效率(如新硬件利用、智能压缩)、查询智能化(如预测性查询、异常模式识别)以及与AI计算平台的深度融合等方面进行探索与优化,以支撑微信及其生态更广阔的未来。