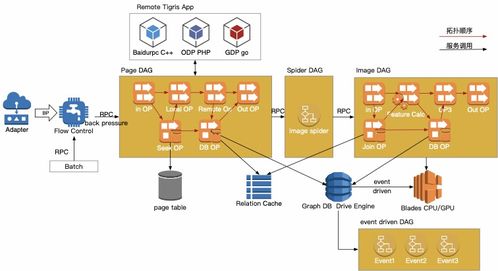
在当今的分布式系统架构中,微服务已成为主流设计范式,而数据库作为数据的最终归宿,两者之间的关系绝非简单的“服务调用存储”那么简单。它们共同构成了现代应用数据处理与存储的核心支撑体系,是一种深度耦合却又职责分明的协同关系。
1. 核心关系:去中心化与数据自治
微服务架构的核心思想是去中心化和单一职责。每个微服务都是围绕特定业务能力构建的、可以独立开发、部署和扩展的小型自治单元。相应地,数据库的所有权也应跟随服务进行去中心化。这意味着,理想情况下,每个微服务应拥有其专属的数据库(或数据库schema),并且该数据库的Schema、数据模型完全由该服务管理,对外部隐藏实现细节。这种“每个服务对应一个数据库”的模式,确保了服务的数据自治性,是实现服务独立演进、技术异构(如A服务用MySQL,B服务用MongoDB)和独立伸缩的基石。
2. 数据处理:从集成数据库到集成API
在传统的单体应用中,多个模块共享同一个数据库,通过直接读写数据表进行集成。这种方式在微服务架构中是一个反模式,因为它会创建隐性的、紧耦合的数据依赖,破坏服务的边界和自治性。
微服务架构下,正确的数据处理逻辑是:服务通过其发布的、定义良好的API(通常是RESTful API或gRPC接口)来提供数据操作能力,而不是直接暴露数据库。当一个服务需要另一个服务所管辖的数据时,它必须通过调用对方的API来实现。这种方式确保了:
- 封装性:数据模型和存储细节被隐藏。
- 解耦:服务可以独立修改其内部数据结构和存储技术,只要API契约保持不变。
- 业务逻辑集中:所有与数据相关的业务规则和验证都集中在服务内部,保证了数据的一致性和有效性。
3. 数据存储:多元化的支撑策略
数据库作为存储支持,其选型和设计需紧密贴合服务的业务特征:
- 多样性:不同的微服务可以根据其数据特征(结构化、文档、图、键值、时序等)选择最合适的数据库,实现多语言持久化。
- 独立伸缩:订单服务的数据库可以独立于用户服务的数据库进行纵向或横向扩展,以应对不同的负载压力。
- CQRS模式:对于读写负载差异巨大的场景,可以采用命令查询职责分离模式,使用不同的存储模型来分别优化写操作(如关系型数据库)和读操作(如Elasticsearch或缓存),进一步提升数据处理性能。
4. 关键挑战与协同模式
这种去中心化的数据管理也带来了挑战,最主要的是数据一致性问题。在跨服务的事务中,无法使用传统的数据库分布式事务(如两阶段提交,2PC),因为它会降低可用性和性能,并与服务自治原则冲突。因此,微服务通常采用最终一致性模型,并通过以下模式协同:
- Saga模式:通过一系列具有补偿操作的服务间本地事务,来管理跨服务的业务事务。
- 领域事件驱动:当一个服务完成其数据变更后,发布一个“领域事件”。其他相关服务订阅这些事件,并异步地更新自己的数据视图,保持数据的最终一致。这通常需要消息队列(如Kafka, RabbitMQ)作为中间件支撑。
- API组合与数据复制:对于需要跨域数据的查询,可以通过API组合器调用多个服务,或在只读场景下,将必要的数据以只读副本的形式异步复制到一个查询专用的数据库中。
5. 数据处理与存储支持服务的架构体现
在系统架构中,数据库并非孤立存在,它与一系列支撑服务共同工作:
- 服务本身:是数据处理逻辑的核心载体,封装了从API到数据访问层(DAO/Repository)的完整链路。
- 配置中心与服务发现:确保服务能动态找到其依赖的数据库连接信息或其他服务的API端点。
- 监控与日志:对数据库连接池、慢查询、事务状态等进行全方位监控,是保障数据层健康的关键。
- 数据流水线:负责处理事件流、ETL和数据备份,构成了数据流动的“大动脉”。
结论
总而言之,微服务与数据库的关系,是一种以业务边界为划分、以API为通信桥梁、以最终一致性为目标的新型协作关系。数据库从传统的“共享中心化存储”角色,转变为“服务专属的支撑性资产”。理解并处理好这种关系,在保障服务自治的通过事件驱动、异步通信等模式优雅地解决数据一致性难题,是构建健壮、可扩展的微服务系统的关键所在。数据处理与存储不再是一个底层技术问题,而是上升为与领域设计、系统架构紧密相连的核心设计维度。